
A Repeatable Solution for Cosmos DB to MongoDB Migration
- Alexander Komyagin

- Oct 13, 2024
- 4 min read

This is an updated version of the original article published on Medium by our CEO, Alexander Komyagin. In this article we'll explore the challenges of building a solution for live migration from Cosmos DB to MongoDB. There are many reasons for users to want to migrate - we will save them for a future article. Here we will focus on technical challenges of what might look like an easy migration between two databases with the same API.
The Reality of Compatibility
Cosmos DB for MongoDB is compatible with a limited subset of MongoDB’s wire protocol, suitable only for the simplest MongoDB applications. This limited compatibility can lead to higher costs and unexpected challenges. Standard MongoDB migration tools (mongomirror, mongosync, etc.) don't work. Mongodump and mongorestore turn out to be painfully slow and can take hours on a relatively small (<100GB) dataset.
Key Concerns for Migration
Migrating production workloads involves addressing several critical concerns:
Avoiding Excessive Downtime
Speeding Up the Migration
Preserving Data Integrity
Implementing a Rollback Plan
Avoiding Downtime
For larger datasets, avoiding downtime during migration is crucial. A live migration approach typically involves the following stages:
Initial Data Copy: Bulk copy the data from the source to the destination.
Capturing Changes: Use Change Data Capture (CDC) to capture changes from the beginning of the data copy process and apply them after the copy is done.
Replicating Changes: Continue replicating changes until the lag between the destination and the source is small enough to cut over.

However, Cosmos DB’s limited support for Change Streams complicates the approach:
No Delete Events: It's recommended that users implement safe-deletes in their applications using a special field to mark deleted documents and set the TTL field for automatic cleanup. They will need to clean up those documents on the MongoDB side as well. In any case, users will likely need to change their application to make it all work. In certain cases, it's possible to compare the source and destination collections side-by-side to determine what was deleted - that's the approach we implemented in Adiom's dsync.
Per-Collection Change Streams: There’s no global or per-database Change Stream support. Each collection needs to have its own Change Stream, requiring writing scripts or coordinating parallel Change Streams. In our tests, we saw performance degradation with more than 10–15 parallel Change Streams on Cosmos DB.
Specific Pipeline Options: Cosmos DB requires using the exact Change Stream pipeline options as specified; otherwise, it won’t work. They also always return the full document, so a replace is needed on the destination. This creates serious risks for gradual cutovers where writes on the destination are allowed early assuming no conflicts. To mitigate these risks, a reliable way to check data integrity is required.
No Timestamps: Timestamps are normally used to calculate the replication lag or delay. Knowing the lag is extremely important to properly time the cutover in live migrations. Since Cosmos DB Change Stream events don't have timestamps, a different method is required. In Adiom's dsync we use event sequencing to calculate the lag.
Lastly, it's important to ensure proper coordination between Change Streams and initial data copy to avoid data loss due to race conditions. In Adiom's dsync, this is done automatically behind the scenes, without requiring any input from the user.
Speeding Up the Migration
Migration speed depends on:
Latency
Level of Parallelization
Provisioned RU/s on the source
Capacity on the destination (CPU, RAM, disk IO)
Network latency to Cosmos DB can significantly impact throughput. In dsync, we parallelize reads from different namespaces. Further, we employ intelligent partitioning strategies to identify sensible split point(s) in the range of _id values, and use parallel range queries for large namespaces to increase speed. Sadly, Cosmos DB’s implementation of the aggregation $sample command does not work correctly, so we can’t do statistical sampling to determine split points programmatically.
Resumability
Dsync tracks synced namespaces and stores resume tokens from Change Streams to avoid restarting the migration process from scratch. This is particularly important during the initial testing phase but also for ensuring reliability.
Data Integrity
With no dbHash support in Cosmos DB, dsync relies on heuristics like count and size, as well as comprehensive per-namespace checksum comparison.
Backout Plan
In Enterprise and mission-critical applications it's more than just a checkbox item. Having an out-of-the-box ability to reverse the synchronization process helps to accelerate planning and testing.
Observability
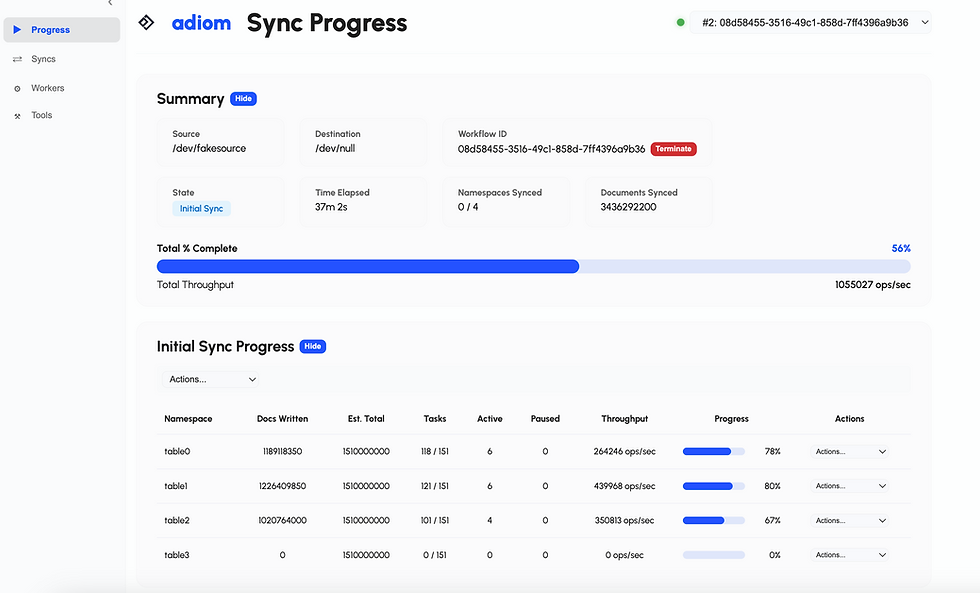
It's important to expose and monitor metrics to identify bottlenecks and ensure direct visibility into the migration process. Bottlenecks can differ between clusters, environments, and sometimes between runs. Dsync offers a CLI- and Web-based progress output, and detailed logs.
Conclusion
Migrating from Cosmos DB to MongoDB is challenging but manageable with the right approach. Addressing key concerns around downtime, speed, data integrity, and backout plans ensures a smooth transition.
At Adiom, we built dsync to help developers and DevOps perform live migrations and real-time replication easily. Dsync is a fast, reliable, easy-to-use and Open Source solution. Using dsync helps to accelerate and derisk projects, and allows teams to get their applications and services onto a new database in minutes instead of months.
Give dsync a try by downloading it from GitHub. It's distributed as a binary that you can just run anywhere, including your laptop, and it doesn't require specialized infrastructure or any complex setup.
Adiom offers help and commercial support on terms that suit your projects best. Get in touch with us here.

Comments