
100TB HBase to MongoDB in Under 48 Hours: Building Support for Large-Scale Online Production Migration
- Alexander Komyagin

- Sep 9, 2025
- 4 min read
Modern enterprises often find themselves needing to migrate massive production datasets between different database technologies. Recently, we tackled one of the most challenging scenarios: migrating over 100TB of data containing 100+ billion records from HBase to MongoDB while maintaining active production traffic. In this article we explore how we built the technical foundation to make this possible.
The Challenge: Scale Meets Complexity
The environment presented several unique challenges:
Massive scale: 100+ TB of data across billions of records in an active HBase cluster
Timeline: Migration should complete in a reasonable amount of time
Zero tolerance for extended downtime: Production systems can't wait months for migration
Complex data transformation: Converting HBase key-value pairs to MongoDB's Extended JSON format
Production reliability requirements: The migration solution itself must be enterprise-grade
HBase Architecture Primer

HBase is a horizontally scalable column-oriented key-value store. Records are organized into tables. Each record or row is identified by its row key, which has to be unique. The data for that row is represented as key-value pairs, where the key is a column name, and the value is arbitrary binary data (byte[]) - it can be a primitive data type like string, an encoded JSON document, an image, or something else. The columns are grouped into column families which are stored into separate files in the underlying HDFS cluster.
For scalability, HBase uses Region Servers, where each Region Server hosts data for a set of particular ranges of row keys that are called Regions. For example, a production HBase cluster can have 32 Region Servers with 256 total Regions, meaning that each Region Server is responsible for 8 Regions.
MongoDB Architecture Primer

MongoDB is a horizontally scalable document-oriented database. MongoDB documents are records in Extended JSON (or BSON), uniquely identified by the _id key. The documents are organized in collections that are logically grouped into databases.
MongoDB supports high availability with the Replica Set architecture. For horizontal scalability MongoDB leverages sharding and Sharded Clusters, where the data is distributed across two or more Replica Sets (Shards) based on ranges (“chunks”) for a particular Shard Key.
MongoDB Atlas is a fully managed cloud database service that simplifies deploying, scaling, and managing MongoDB databases in the cloud.
Technical Requirements for HBase to MongoDB Migration
Building a system capable of handling this scale required addressing seven critical requirements:
Minimize Downtime: We implemented a CDC (Change Data Capture) stream coordinated with initial data copy to ensure no changes are lost during migration.
Scale and Performance: With billions of records, every inefficiency scales exponentially. The migration data path required optimization down to the microsecond level.
Repeatability: Large modernization efforts involve iterations across development, UAT, and production environments, demanding consistent, predictable outcomes.
Resumability and Resilience: Production migrations must handle failures gracefully without restarting from scratch.
Reverse Sync: A cooling-off period after migration requires syncing changes back to HBase with fallback capability.
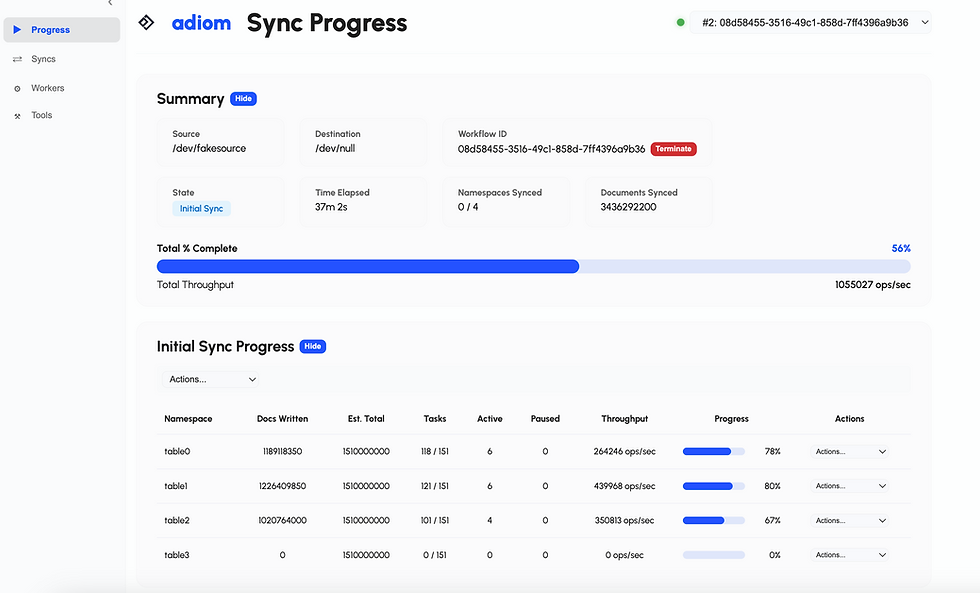
Observability: Real-time progress tracking, ETAs, and performance bottleneck identification are essential for production planning.
Throttling: Impact on the source system serving live traffic must be carefully controlled.
Solving the HBase CDC Challenge
HBase's architecture presented a unique technical hurdle: it doesn't support pull-based change streams and only offers push-based replication. Our solution leveraged HBase's existing replication mechanism with a creative twist:
We created a "fake" HBase cluster with a modified write path that writes to Kafka instead of storage
The original HBase cluster replicates to this fake cluster using standard HBase replication
This architecture transforms HBase's push-based replication into Kafka's pull-based change stream
Multiple Kafka topics with partitioned streams support high CDC throughput
The Dsync Architecture
Our solution centers on a scalable enterprise-grade architecture built with several key components:
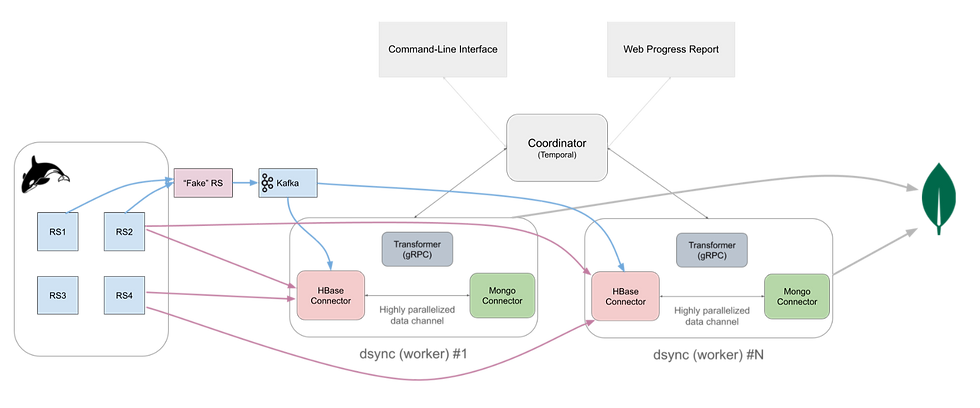
Temporal Workflow Engine: Provides durable workflow orchestration for complex, long-running migration processes.
Task-Based Parallelization: Work splits into tasks based on source HBase regions, with multiple dsync workers processing tasks in parallel.
YAML-Based Transformations: Data transformations and filtering are defined in YAML using CEL (Common Expression Language), making complex data model adjustments manageable at scale.
Automatic CDC Switching: After initial data copy completion, the system automatically switches to replicating CDC changes from the pre-copy timestamp, ensuring zero data loss.
Lightweight deployment: Even when deployed at scale, Dsync only uses compute (CPU + RAM) and doesn’t require persistent storage, making it easily deployable on commodity VMs or containers.
Observability and Reporting: Dsync provides an intuitive web-based real-time progress report along with granular metrics via OpenTelemetry.


Performance Results
Our technical development has achieved impressive benchmarks:
2 million writes/second replication capability to a 7xM200 destination Atlas cluster
24-48 hour migration window for 100 billion records
Efficient resource utilization: 10 worker nodes (16 CPUs, 64GB RAM each) plus 1 coordinator node (8 CPUs, 32GB RAM)
Best Practices for Large-Scale Migration
Through this development process, we've identified key practices for successful large-scale database migrations:
Plan for Iterations: Design for multiple runs across Dev, UAT, and production environments with several dry runs before go-live.
Prioritize Repeatability: Use migration solutions that enable fast, consistent execution across different environments.
Balance Accuracy and Speed: Develop data reconciliation strategies that acknowledge the trade-offs inherent in large-scale operations.
Modularize Workflows: Split large tables into separate workflows for easier operational management.
Size Appropriately: Revise production sizing based on actual object sizes discovered during development and testing phases.
Follow MongoDB Ingestion Optimization: Overprovision destinations, disable backups during migration, set oplog to fixed size, and build indexes during the CDC phase rather than initial load.
Looking Forward
The HBase connector is now available in preview - a major breakthrough for large-scale database migrations. This technology helps companies modernize their databases on a short and predictable timeline, and without compromising operational stability.
By combining Temporal workflows, intelligent CDC, and highly parallel processing, we've built a platform that can handle even the toughest migration challenges. We're continuing to improve dsync, making migrations that were once impossible now achievable and reliable.
Make sure to check out the demo video of the migration process:
The HBase connector is available in preview. For more information about the scalable deployment and dsync, please consult our documentation. If you need assistance with HBase or other database migrations, please contact us.
Adiom is a MongoDB technology partner for database migrations to MongoDB Atlas. We deliver MongoDB migration services at global scale along with our partners at Delbridge Solutions.

Comments